
11.1 최소 비용 신장 트리
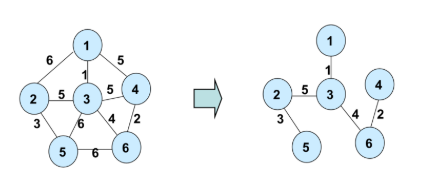
● 신장 트리(spanning Tree): 그래프 내의 모든 정점을 포함하는 트리
- 모든 정점들이 연결되어 있어야 한다.
- 사이클을 포함하여선 안된다.
- n개의 정점을 정확히 (n-1) 개의 간선으로 연결한다.
- 하나의 그래프에는 많은 신장 트리가 존재 가능하다.
- dfs나 bfs를 수행하면서 탐색 도중에 사용된 간선들을 모으면 신장 트리를 만들 수 있다.
- 신장 트리 = 그래프의 최소 연결 부분 그래프 = n-1개의 간선으로 연결되어 있으면 필연적으로 신장 트리
● 최소 비용 신장 트리 (MST: minimum spanning tree): 신장 트리 중 사용된 간선들의 가중 치 합이 최소인 신장 트리
- 신장 트리의 조건들을 마찬가지로 지켜야 한다.(n-1개의 간선, 사이클을 포함하면 안 됨 등)
- 최소 비용 신장 트리를 구하는 방법으로는 Kruskal과 Prim이 제안한 알고리즘이 대표적으로 사용된다.
♠ 398p Quiz

11.2 Kruskal의 MST 알고리즘
● Kruskal 알고리즘
- 탐욕적 방법(greedy method)을 사용
* 탐욕적 방법: 선택마다 그 순간 가장 좋다고 생각되는 것을 선택함으로써 최종적인 해답에 도달하는 것
- 우선, 간선들을 가중치의 오름차순으로 정렬
- 최소 비용의 간선으로 구성됨과 동시에 사이클을 포함하지 않는다는 조건에 근거하여
각 단계에서 사이클을 이루지 않는 최소 비용 간선을 선택
- 해당되는 간선은 MST 집합에 추가
● Union-find 연산과 구현 (사이클 체크)
- 간선의 양끝 정점이 같은 집합에 속하면 해당 간선을 추가할 경우 사이클이 형성된다.
따라서 Union-find 알고리즘을 통해 간선의 양끝 정점이 같은 집합에 속하는 지 검사한다.
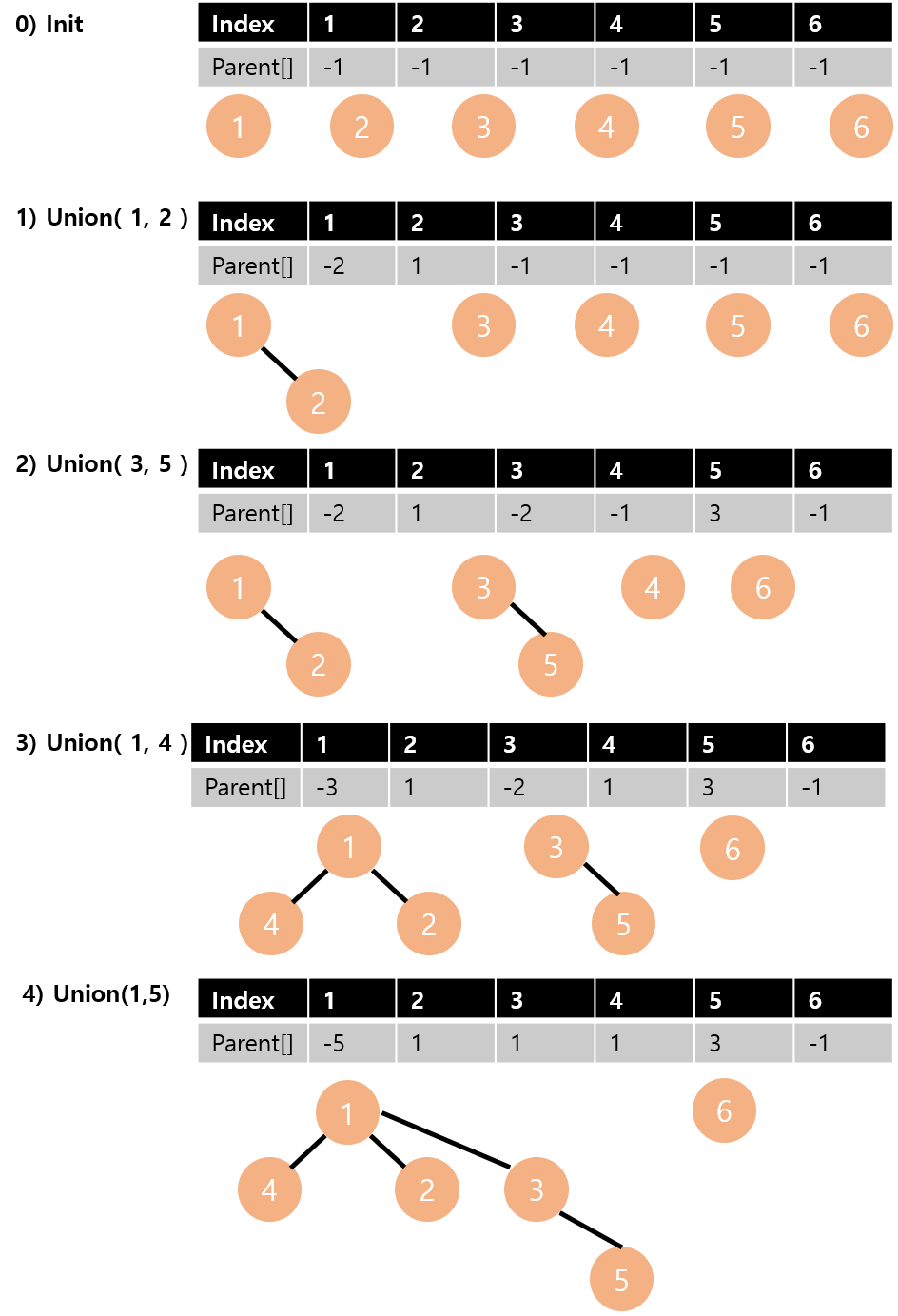
집합 구현을 위해 트리 형태 사용
- 부모 노드를 알기 위해 각 노드에 대해 그 노드의 부모에 대한 포인터를 저장.
- 1차원 배열로 부모 노드의 index를 저장.
- 초기값은 -1로, 부모노드가 없으면 -1
union(x,y) = 원소 x와 y가 속해있는 집합을 입력으로 받아 2개의 집합의 합집합을 만들기
find(x) = 원소 x가 속해있는 집합을 반환
int set_find(int curr){
if(parent[curr] == -1) return curr;
while(parent[curr]!=-1){
curr = parent[curr];
}
return curr;
}
void set_union(int a, int b){
int root1=set_find(a);
int root2=set_find(b);
if(root1 != root2){
parent[root1]= root2;
}
}
간선들을 weight에 대해 오름차순 정렬하여야 해서 compare함수를 구현한 뒤 qsort함수를 사용하였다.
void qsort (void *base, size_t nel, size_t width, int (*compare)(const void *, const void *);base : 정렬할 배열의 포인터
nel: 배열의 원소 수
width: 배열의 한 원소의 크기
compare:
int compare(const void* a, const void* b){
struct Edge* x = (struct Edge*)a;
struct Edge* y = (struct Edge*)b;
return (x->weight - y->weight);
}b가 a보다 크면 return값이 음수,
a가 b보다 크면 return값이 양수이고 a와 b의 위치를 바꾼다.
void kruskal(GraphType *g){
int edge_accepted =0;
int uset, vset;
struct Edge e;
set_init(g->n);
qsort(g->edges,g->n,sizeof(struct Edge),compare);
printf("kruskal minimum spanning tree \n");
int i=0;
while(edge_accepted< (g->n -1)){
e = g->edges[i];
uset = set_find(e.start);
vset = set_find(e.end);
if(uset != vset){
printf("간선 (%d,%d) %d 선택\n", e.start,e.end, e.weight);
edge_accepted++;
set_union(uset,vset);
}
i++;
}
}간선의 수는 무조건 n-1개이므로 해당 조건으로 while문을 돌린다.
서로 속한 집합이 다르면 edge_accepted를 증가시켜 주고, 두 개의 집합을 합친다.
● 시간 복잡도 분석
간선을 정렬하는 시간에 좌우되기 때문에 효율적인 정렬 알고리즘 사용시 (|e|log2|e|)의 시간복잡도를 가진다.
♠ 408p Quiz
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 간선 | -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 |
| (0,7) | 7 | -1 | -1 | -1 | -1 | -1 | -1 | -1 |
| (1,5) | 7 | 5 | -1 | -1 | -1 | -1 | -1 | -1 |
| (3,7) | 7 | 5 | -1 | 7 | -1 | -1 | -1 | -1 |
| (1,2) | 7 | 5 | -1 | 7 | -1 | 2 | -1 | -1 |
| (4,5) | 7 | 5 | -1 | 7 | 5 | 2 | -1 | -1 |
| (4,7) | 7 | 5 | 7 | 7 | 2 | 2 | -1 | -1 |
| (5,6) | 7 | 5 | 7 | 7 | 2 | 2 | -1 | 6 |
11.3 Prim의 MST 알고리즘
● Prim 알고리즘
- 시작 정점에서 출발하여 신장 트리 집합을 단계적으로 확장
- 앞 단계에서 만들어진 신장 트리 집합에, 인접한 정점들 중 최저 간선으로 연결된 정점 선택
● vs Kruskal
Kruskal 알고리즘은 간선 기반 알고리즘인 반면 Prim 알고리즘은 정점 기반 알고리즘
Kruskal 알고리즘은 이전 단계의 신장트리와는 상관없이 무조건 조건을 만족하는 최저 간선을 선택하는 반면
Prim 알고리즘은 이전 단계에서 만들어진 신장 트리를 확장
● Prim 알고리즘 구현
- distance 배열의 시작 노드값은 0, 나머지 노드들은 무한대의 값을 가진다.
- 우선순위 큐에 distance 배열값을 우선순위로 하여 모든 정점을 삽입한다.
- while 루프로 우선순위 큐에서 가장 작은 distance값을 가지는 정점을 끄집어내어 트리 집합에 추가한다.
- 정점이 트리 집합에 추가되면 인접한 정점들의 distance 값을 변경한다
기존 distance[v] 보다 간선(u, v)의 가중치 값이 적으면 distance[v] = 간선 (u, v)의 가중치로 바꾸어준다.
- 큐의 모든 정점들이 소진될 때 까지 정점 개수 n만큼 반복한다.
int get_min_vertex(int n){
int v,i;
for(i=0; i<n; i++){
if(!selected[i]){
v=i;
break;
}
}
for(i=0;i<n;i++){
if(!selected[i] && (distance[i]<distance[v])){
v = i;
}
}
return v;
}
void prim(GraphType *g, int s){
int i,u,v;
for(u=0; u<g->n; u++){
distance[u] = INF;
}
distance[s]=0;
for(i=0; i<g->n; i++){
u = get_min_vertex(g->n);
selected[u] = TRUE;
if(distance[u]==INF) return;
printf("정점 %d 추가\n",u);
for(v=0;v<g->n;v++){
if(g->weight[u][v] !=INF){
if(!selected[v] && g->weight[u][v]<distance[v]){
distance[v] = g->weight[u][v];
}
}
}
}
}
get_min_vertex(int n)
- 아직 선택되지 않은 가장 빠른 인덱스 노드를 찾는다
- prim함수에서 방문한 노드의 인접노드들의 distance들은 갱신되어 있으므로
아직 방문되지 않은 노드들의 distance들을 비교하면서 가장 작은 distance를 가지는 정점을 반환한다
prim(GraphType* g, int s)
- 모든 distance들을 INF로 초기화시켜준 다음 시작노드의 distance는 0으로 설정한다.
- 최소 distance를 가지는 정점을 selected에 넣고, 인접 노드들의 가중치가 INF가 아닌 노드들을 찾는다.
- 해당 노드들이 아직 방문되지 않은 노드이면 distance와 방문 노드에서부터의 가중치를 비교하여
더 작은 값을 distance로 바꾼다.
- for문을 돌면서 distance를 비교하여 get_min_vertex가 선정되어 return 될 것이다.
main
- 이차원배열을 선언과 동시에 초기화 한다.
- 같은 행에 속하는 값들은 중괄호 { }로 묶어주고 행별 값들은 쉼표로 구분한다.
● Prim 알고리즘의 분석
-주 반복문이 정점의 수 n번만큼, 내부 반복문이 n번 반복하므로 O(n^2)의 복잡도를 가진다.
-Kruskal의 O(elog2e)와 비교하면, 희소 그래프일 경우 Kruskal 알고리즘이 유리하고
밀집 그래프일 경우 Prim 알고리즘이 유리하다.
♠ 414p Quiz 01
0 -> 7 -> 3 -> 2 -> 1 -> 5 -> 4 -> 6
'CS > Data Structure' 카테고리의 다른 글
| [C언어로 쉽게 풀어쓴 자료구조] 연습문제 11강 (1) | 2023.12.17 |
|---|---|
| [C언어로 쉽게 풀어쓴 자료구조] Chapter11. 그래프 II (2) (0) | 2023.12.15 |
| [C언어로 쉽게 풀어쓴 자료구조] 연습문제 10강 (0) | 2023.12.12 |
| [C언어로 쉽게 풀어쓴 자료구조] Chapter10. 그래프 I (2) (0) | 2023.12.08 |
| [C언어로 쉽게 풀어쓴 자료구조] Chapter10. 그래프 I (1) (1) | 2023.12.08 |